Setting Up a Cluster¶
Even though it's possible to run ViyaDB on a single node, it's usually required to run several database instances in order to be able to:
- Scale in case aggregated dataset doesn't fit into a single machine's RAM.
- Scale out concurrent queries by spreading them between different workers.
- Failover on data center failure.
This page describes how ViyaDB works when running in a cluster mode.
Architecture¶
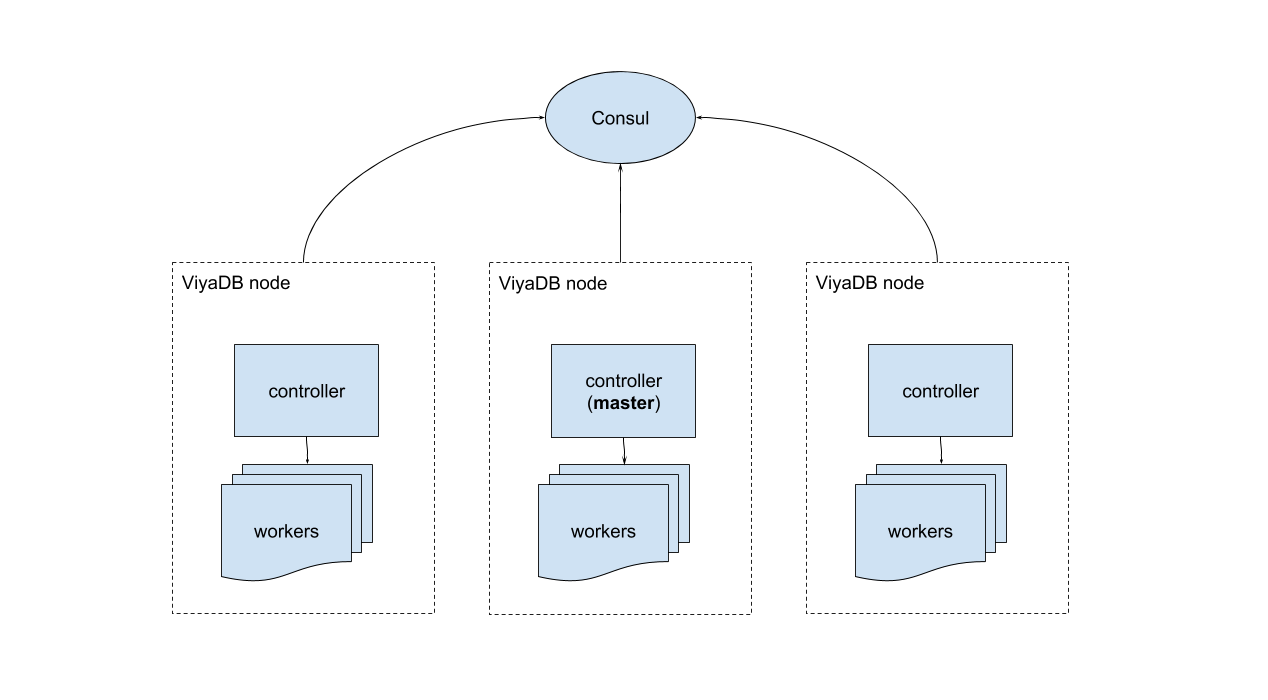
ViyaDB implements shared nothing architecture. That means that the data is partitioned and spread between independent workers.
Components¶
Consul¶
Consul is used as a coordination service as well as for storing cluster configuration.
There were three different options for coordination service at the beginning: Zookeeper, Consul and etcd, but the choice was made in favor of Consul for its:
- Installation and configuration simplicity.
- Great Web interface.
- Out of the box service registration and lookup support.
Worker¶
Worker is a ViyaDB process that keeps a partition of data in RAM. Every such process is attached to it's own CPU core (using CPU affinity) for achieving better cache locality.
Every worker listens on its own HTTP port, where it provides a service for loading and querying the data it keeps.
Controller¶
Controller is the main process that launches ViyaDB workers on a single node, and takes care of keeping them alive. In addition, this process is responsible for coordination between database nodes using Consul. One of cluster controllers becomes a leader.
Controller can act as query aggregator, which means that it can be queried directly, and a query will be sent to workers containing required data partitions, then the result will be combined and returned back to a user.
Communication with workers is performed using HTTP API.
Running¶
Let's run a cluster of ViyaDB nodes, and load 1 billion of user events into it.
Consul configuration¶
First, you must have Consul installed somewhere.
Create the following two keys in Consul, which represent ViyaDB cluster configuration:
viyadb/clusters/cluster001/config
{ "replication_factor": 1, "workers": 32, "tables": ["events"] }
viyadb/tables/events/config
{ "name": "events", "dimensions": [ {"name": "app_id"}, {"name": "user_id", "type": "uint"}, { "name": "event_time", "type": "time", "format": "millis", "granularity": "day" }, {"name": "country"}, {"name": "city"}, {"name": "device_type"}, {"name": "device_vendor"}, {"name": "ad_network"}, {"name": "campaign"}, {"name": "site_id"}, {"name": "event_type"}, {"name": "event_name"}, {"name": "organic", "cardinality": 2}, {"name": "days_from_install", "type": "ushort"} ], "metrics": [ {"name": "revenue" , "type": "double_sum"}, {"name": "users", "type": "bitset", "field": "user_id", "max": 4294967295}, {"name": "count" , "type": "count"} ], "partitioning": { "columns": [ "app_id" ] } }
ViyaDB nodes¶
Then, let's launch four AWS EC2 instances of type r4.2xlarge. This instance type has 8 vCPU, which will allow us to have 8 workers per host (32 workers in total). This will translate into having 32 partitions if using a single replica per partition.
ViyaDB is built against g++-7, that's why it's easier to use one of Ubuntu Artful (17.10) AMI provided by Canonical. Make sure, all TCP ports of ViyaDB nodes are open to each other. Also, make sure there’s enough disk space for downloading and extracting several tens of gigabytes of JSON files representing user events.
Once all four machines are running, proceed with the following steps on every one of the nodes.
Install g++-7 by running the following commands:
apt-get update
apt-get install g++-7
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60 --slave /usr/bin/g++ g++ /usr/bin/g++-7
Create file /etc/viyadb/store.json with the following contents (replace consul-host with real Consul hostname):
{ "supervise": true, "workers": 8, "cluster_id": "cluster001", "consul_url": "http://consul-host:8500", "state_dir": "/var/lib/viyadb" }
Download ViyaDB package, and extract it:
curl -sS -L https://github.com/viyadb/viyadb/releases/download/v1.0.0-beta/viyadb-1.0.0-beta-linux-x86_64.tgz | tar -zxf -
Run ViyaDB instance:
cd /opt/viyadb-1.0.0-beta-linux-x86_64
./bin/viyadb /etc/viyadb/store.json
Loading data¶
There's utility under bin/ directory of ViyaDB package called vsql, which can be used for sending SQL queries to ViyaDB cluster.
Open the SQL shell utility, and connect it to one of ViyaDB hosts:
/opt/viyadb-1.0.0-beta-linux-x86_64/bin/vsql viyadb-host 5555
We have 1 billion of user events stored in gzipped TSV format in AWS S3. To load them, issue the following query:
ViyaDB> COPY events (app_id, user_id, event_time, country, city, device_type, device_vendor, ad_network, campaign, site_id, event_type, event_name, organic, days_from_install, revenue, count) FROM 's3://viyadb-test/events/input/'
Querying¶
Disclaimer: all queries were recorded when running for the second time to exclude query compilation time from the total query running time.
Count different event types for a given list of applications:
ViyaDB> SELECT event_type,count FROM events WHERE app_id IN ('com.skype.raider', 'com.adobe.psmobile', 'com.dropbox.android', 'com.ego360.flatstomach') ORDER BY event_type DESC event_type count ---------- ----- session 117927202 install 263444 inappevent 200466796 impression 58431 click 297 Time taken: 0.530 secs
Find 5 top cities in USA by install count for a specific application:
ViyaDB> SELECT city,count FROM events WHERE app_id='com.dropbox.android' AND country='US' AND event_type='install' ORDER BY count DESC LIMIT 5; city count ---- ----- Clinton 28 Farmington 20 Madison 18 Oxford 18 Highland Park 18 Time taken: 0.171 secs
Find top 10 ad networks for a specific application:
ViyaDB> SELECT ad_network, count FROM events WHERE app_id='kik.android' AND event_type='install' AND ad_network <> '' ORDER BY count DESC LIMIT 10; ad_network count ---------- ----- Twitter 1257 Facebook 1089 Google 904 jiva_network 96 yieldlove 79 i-movad 66 barons_media 57 cpmob 50 branovate 35 somimedia 34 Time taken: 0.089 secs
Find user retention (number of distinct user sessions) for the first week, per three major ad networks:
ViyaDB> SELECT ad_network, days_from_install, users FROM events WHERE app_id='kik.android' AND event_time BETWEEN '2015-01-01' AND '2015-01-31' AND event_type='session' AND ad_network IN('Facebook', 'Google', 'Twitter') AND days_from_install < 8 ORDER BY days_from_install, users DESC ad_network days_from_install users ---------- ----------------- ----- Twitter 0 33 Google 0 20 Facebook 0 14 Twitter 1 31 Google 1 18 Facebook 1 13 Twitter 2 30 Google 2 17 Facebook 2 12 Twitter 3 29 Google 3 14 Facebook 3 11 Twitter 4 27 Google 4 13 Facebook 4 10 Twitter 5 26 Google 5 13 Facebook 5 10 Twitter 6 23 Google 6 12 Facebook 6 9 Twitter 7 22 Google 7 12 Facebook 7 9 Time taken: 0.033 secs
Real-Time Data Processing¶
To see the complete real-time data processing architecture based on ViyaDB cluster, please visit next section.